You are reading articles by Simplificator, a Swiss-based custom software development agency. Here we write about the problems we solve and how we work together.
So organisieren wir uns in dieser aussergewöhnlichen Zeit
Es ist eine Zeit mit vielen Herausforderungen, sowohl geschäftlich als auch im privaten Umfeld. Man startet in den Tag mit einem Update zu den Zahlen rund um das Coronavirus und wird täglich mit einem Anstieg der Erkrankten und Todesfälle konfrontiert. In der Schweiz sind inzwischen 56 Personen am Coronavirus gestorben, 6113 sind infiziert. (Stand 22.03.2020, 10:30 Uhr) Der Bundesrat hat die «ausserordentliche Lage» ausgerufen.
Um das Wachstum dieser Zahlen zu verlangsamen, hat der Bundesrat verschiedene Massnahmen ergriffen - unter anderem das Einschränken des öffentlichen Lebens. Doch physische Distanz heisst nicht gleichzeitig soziale Distanz. Gerade in Zeiten wie diesen ist Kommunikation extrem wichtig. Gemäss einem unserem Grundsätze “dare to question” steht bei uns auch in der aktuellen Situation Kommunikation an oberster Stelle. Wir entwickeln nicht einfach drauf los, sondern wir finden zuerst heraus, was unsere Kunden benötigen. Dazu gehört auch, dass man als Team eng zusammenarbeitet und sich permanent austauscht.
Doch wie erreichen wir das trotz Homeoffice bzw. den Einschränkungen durch das Coronavirus?
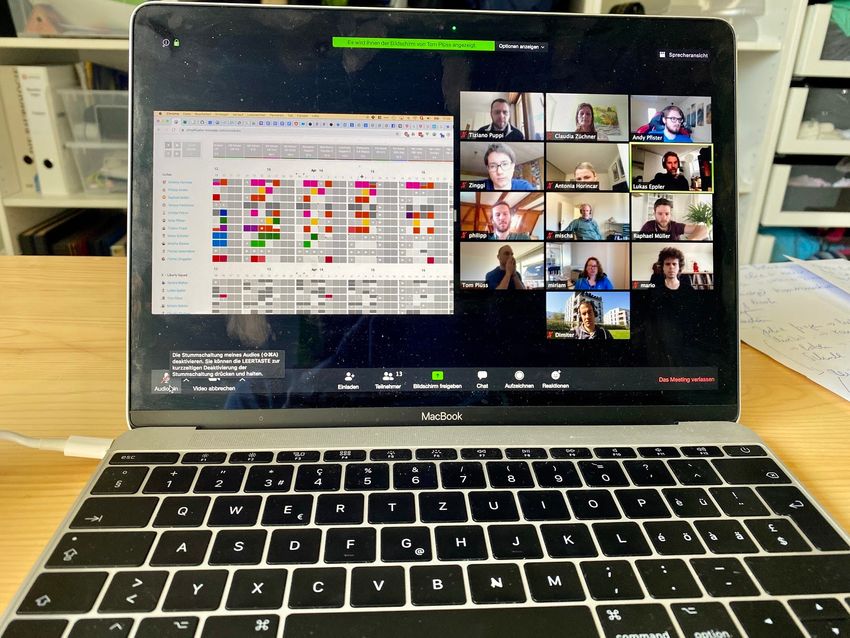
Unseren gemeinsamen Tag beginnen wir jeden Morgen mit einem virtuellen Standup Meeting via Zoom. Das Ziel ist ein kurzer Austausch über die Aufgaben jedes Mitarbeiters und jeder Mitarbeiterin und ob man auf Projekten zusammenarbeiten kann, um sich gegenseitig zu unterstützen. In diesem Zusammenhang haben wir auch einen Blick auf Moco, unser Planungs- und Zeiterfassungstool. Die Planungsübersicht zeigt uns übersichtlich welcher Mitarbeiter in den kommenden Tagen auf welchem Projekt arbeitet.
Da auch ein Arbeitstag im Homeoffice nicht um 12 Uhr vorbei ist, treffen wir uns im Team noch einmal am frühen Nachmittag zu einem virtuellen Coffee-Break. Diese tägliche Kaffeepause gibt Raum für Themen, die nicht zwingend mit der Arbeit zu tun haben und fördern das soziale Miteinander in dieser aussergewöhnlichen Situation.
Regelmässige Videocalls über den Tag verteilt helfen uns, uns in kleineren Teams abzusprechen, Fragen zu stellen und uns auszutauschen sowie etwas zu diskutieren. Auch mit Kunden und Leads stimmen wir uns aktuell über diesen Kanal ab.
All unsere Systeme sind von zu Hause erreichbar und wir sind uns bereits gewohnt ab und an remote zu arbeiten. Slack erweist sich dabei für uns als unerlässliches Tool zur textbasierten Kommunikation untereinander als auch mit unseren Kunden. Unser Grundsatz “Collaborate closely” nimmt noch mehr an Bedeutung zu, damit wir in dieser Zeit die Bedürfnisse unserer Kunden erkennen und auch lösen können. Wir stehen in direktem, regelmässigen Kontakt mit jedem Einzelnen und versuchen dort zu helfen, wo es uns braucht.
Doch neben all den technischen Möglichkeiten, die uns die Zusammenarbeit erleichtern ist es wichtig, dass man sich zu Hause ein geeignetes Umfeld zum Arbeiten schafft. Ein separater Arbeitsplatz an dem man sich besser auf die Arbeit konzentrieren kann, ist enorm hilfreich. Darüber hinaus hilft ein strukturierter Tagesablauf mit fixen Pausen z.B. für Sport.
Allerdings sehen wir auch, dass Homeoffice nicht für alle Branchen umsetzbar ist. Was macht der Blumenladen um die Ecke, dessen Lager mit frischen Blumen voll ist? Was macht das Geschäft mit Kinderkleidern, welches die aktuelle Frühjahrskollektion bestellt, aber nun stationär nicht verkaufen darf? Ein Webshop kann hier vielleicht Abhilfe schaffen, so dass auch diese Unternehmen weiterhin für ihre Kunden da sein können. Wir sind dabei, uns einfache Lösungen zu überlegen.
Für Unternehmen, die von zuhause aus arbeiten können und ihre eigenen Server im Büro haben, lohnt es sich, ein VPN einzurichten und sicherzustellen, dass jeder Mitarbeiter auf einfache Art auch remote Zugriff hat.
Wir sehen, dass besonders in Zeiten des Coronavirus eine enge Zusammenarbeit und der Austausch untereinander wichtig sind. Natürlich wären direkte Kontakte vor Ort in vielen Fällen besser - die digitalen Varianten sind aber gute Alternativen.
Gerne beraten und unterstützen wir, sollte jemand Hilfe benötigen in Bezug auf Remote Collaboration - technischer oder auch organisatorischer Art.
Physical distancing doesn't mean social distancing - rather collaborate closely.
There is one obvious way that makes it easier for coders to write blog posts.
We tried everything before: First we wrote our own thing. Of course. It was a simple database and we wrote our own
markup parser - well, it was 12 years ago and there wasn't much around rails yet. And for the first year or so, it
was just a blog. After some time
Radiant CMS came out and we gave it a spin. It worked, it was quite ok. We struggled greatly
with the multilingual part, but had something running. Unfortunately I don't have screenshots of the blog - and the
wayback machine
has no recollection of our CSS, so I won't post screenshots here. It wasn't grand either, but already fairly political
(I ranted about the SUISA fees, which is now the reason why it is now apparently legal to use torrent software in Switzerland). I found a screenshot of the front page:
But it was also very technical, we were proud of working with Ruby on Rails, almost as much as we're proud now of
working with Elixir and Phoenix.
We then had the idea to link the different aspects of our work together: We write projects, using technologies,
with customers. Page visitors should be able to see what we do, who we are, and the connecting link was technology.
Several developers will develop a project, one project was always for one customer, one customer might have many projects. There will be several technologies used
(Ruby on Rails, Javascript in most cases, but also jQuery, Cucumber, RSpec, Heroku and many more). So we linked them
together. To make sure the links stay consistent we rolled our own thing again.
Simple is not easy. So our page grew, and it became apparent that we're inflexible. It got out of date. It was slow.
It wasn't ideal for all this new fancy SEO strategies. We expanded and tweaked. And our own system survived. But
we found out that we're so far behind that it's hard to catch up. Was it worth it?
We did a redesign, mostly to support mobile, and streamlined everything optically. But then we stopped:Our leads come from connections and people who experienced working with us, rarely through google. We needed to not
suck on our page, so we don't deter anyone, but even if we would triple our leads from the web site it would contribute
close to nothing to our bottom line. So we focused on other topics. To ease some pain with the blog, we moved it
to WordPress. A complete admission of defeat.
Last summer, things started to move again. We changed the way we organize ourselves and how we take decisions (more about
that later). So some of us took initiative and started rewriting, taking the best technologies available
to create a top-of-the-line solution, with deployment pipelines, static rendering, CDN and the best
of all, our blog content is now on GitHub. We can write however we like with the editor of our choice,
issue pull requests for feedback, and publish with a commit. And suddenly, we (or at least I) write blog posts again.
The issue why we procrastinate about stuff like writing blog posts is not the technology. Our habits and what we love to do define what comes easy. Procrastination is often a sign that we strayed away from what we're good at. We're not procrastinating about what we love to do. If that is writing code, committing and writing pull requests, let us hook into that.
So now, to write this blog post, I added a file to our repository (which is public on GitHub, by the way), and issued a pull request. I have asked others to pitch in, and after I took in all the feedback I got, this post will
be merged and published.
This is a way to make it easy for coders to publish blog posts.
To have a process like that is not easy to set up. But when it's done it is as it should be: simple.
Cypress.io has very nice tooling for testing. We have been experimenting with it in various projects, one of which is a Rails application.
Cypress is not the obvious choice for Rails, since Rails comes with system tests out of the box since version 5.1. Before that Capybara was also not hard to set up.
Over the years we've gone back and forth on Selenium-based tests mainly due to how easily they can become slow and flaky. We're now trying to see if Cypress can help in this aspect.
There are a few subtleties about integrating Rails with Cypress.
First of all, if your frontend communicates with the backend through an API, Cypress makes it easy to test the frontend in complete isolation. In this application however we are dealing with a classic server-rendered user interface that achieves some of the interactivity with "sprinkles" of JavaScript. That means that we have to run the Rails server in order to test the UI.
Cypress knows nothing about the backend and expects it to be running already. We can get there with a helper script:
#!/usr/bin/env bash
RAILS_ENV=test bundle exec rake db:environment:set db:create db:schema:load bundle exec rails server -e test -p 5002
Then we tell Cypress how to find it using the baseUrl setting in cypress.json:
{"baseUrl":"http://localhost:5002"}
Cleaning up between tests
Because the test backend is a long-running process and the tests can (indirectly) modify the database, we need to make sure every test starts with a clean slate.
One way to do it is to expose an API that is only available during tests.
# config/routes.rb
Rails.application.routes.draw do # ... ifRails.env.test? require'test_routes' define_test_routes end end
The necessary routes are defined in a separate file on purpose. First, the file name itself warns that they are for the test environment. Second, the conditional inclusion in the router is easy to scan and there's no chance to accidentally define test routes outside this conditional, no matter how many there are.
Let's define a route for the database cleanup:
# lib/test_routes.rb
defdefine_test_routes Rails.logger.info 'Loading routes meant only for testing purposes'
namespace :cypressdo delete 'cleanup', to:'cleanup#destroy' end end
The controller contains this:
# app/controllers/cypress/cleanup_controller.rb
classCypress::CleanupController<ActionController::Base defdestroy if!Rails.env.test? return head(:bad_request) end
tables =ActiveRecord::Base.connection.tables tables.delete 'schema_migrations' tables.eachdo|t| ActiveRecord::Base.connection.execute("TRUNCATE #{t} CASCADE") end
head :ok end end
The guard clause is there to be extra careful, because we then truncate all application-defined tables! We keep the migrations information intact and remove the data from all other tables. No need for a gem like database_cleaner.
Speaking about logging in, Cypress encourages you to "cheat" as much as possible in the test setup phase. (See Cypress best practices) Logging in using through the user interface is reserved for those tests that actually verify the login flow. Every other test can use a backdoor.
Login helper
# lib/test_routes.rb
deftest_routes namespace :cypressdo # ... resource :sessions, only:%i[create] end end
# app/controllers/cypress/sessions_controller.rb
classCypress::SessionsController<ActionController::Base defcreate sign_in(user) render json: user end
private
defuser if params[:username] User.find_by!(username: params.fetch(:username)) else User.first! end end end
The corresponding command can be defined as follows:
Now we can quickly login in tests with cy.login() (or cy.login('billie') to log in as 'billie').
Additional tips
You may have noticed that the /cypress/factories endpoint returns a JSON representation of created record. This makes it easier to inspect the data in the Cypress test runner interface (open the developer tools, and expand the response logged in the console).
It also allows you to use the returned data in the test, e.g.:
Another thing that makes testing smoother is configuring the Rails server to reload code on every request in the test environment. By default code caching is enabled and speeds up the test suite. However, if you are also changing backend code while writing Cypress tests, you'd have to manually restart the server on every change. We use the configuration below to get the best of both.
# config/environments/test.rb
Rails.application.configure do config.cache_classes =!ENV['CYPRESS_DEV'] end
During test driven development, we can get code reloading with CYPRESS_DEV=yes bin/test_server. On CI and when running tests locally, we omit the environment variable which leads to the default Rails test behaviour.
This week I had the pleasure of attending Finance 2.0, which is the leading FinTech conference in Switzerland. In this post, I’ll be sharing the content of the conference from a software developer point of view.
The Customer is King
The slogan of the conference was “Facing a paradigm change: From CRM, the classic Customer Relationship Management, to CMR, a Customer-Managed Relationship.“ That sums up really well what most of the speakers addressed: the customer is in the driver’s seat and if the financial institutions do not cater to their needs, they will lose their reason of existence. This paradigm change has motivated the industry to be innovative and launch products that the users want to use.
The saying “The Customer is King” is no news for software developers. We know that if the app or software we are designing is not what the users want, they will simply not use it. With consumer loyalty on the decline, the financial industry has begun to focus on customer-centric tools just as we have been doing in software engineering.
Open Banking
The topic “Open Banking” was mentioned frequently. More and more banks are letting third-party companies (mostly startups) access their financial institution via open APIs to develop innovative tools. There was a panel about the security risks associated with open banking and how to deal with it.
Open Banking is an interesting topic. The panel discussion clearly showed that a market potential exists for innovative startups or software developers building services in collaboration with financial institutions. As a software agency with a lot of experience in simplifying complex processes, these are interesting prospects.
ICO’s and blockchain
I was rather surprised that there weren’t more speeches about the possibilities the blockchain technology offers for the financial industry. Instead, in a panel discussion titled “ICO: A bubble or the future of funding?”, it was pointed out how crazy it is for startups collecting millions in investments without having produced anything except an unreadable white paper.
The underlying skepticism proofs that as a producer of digital products it’s not enough to simply groom oneself with the buzzword “Blockchain” to get into business with financial institutions. Only a valid business case can succeed in convincing potential customers.
Living innovation
I was thoroughly impressed by SIX Group and their innovation initiative. Here’s a large player in the financial industry not only talking about being innovative but actually living up to that claim. I particularly enjoyed the pitches from the winners of the SIXHackathon that took place the preceding weekend. The prototypes they developed in only 48 hours were very interesting and the level of (tech) talent from the team members was quite impressive.
Summary
The financial industry acknowledges that the times are changing and that it’s time to focus on the customer and their needs. Digital transformation is only one of the means to take this change into account, but it’s precisely what Simplificator is good at. These times are really exciting for us and we look forward to excelling our partners' businesses and making their customers happy.
As I’m writing this blog post, I’m ending my 6-month internship at Simplificator as a software developer. A month ago I turned 34. Yes, you read correctly, at an age where most employees are looking to boost their careers, I decided to go back to square one and learn how to code. But why did I choose to do so?
I’ve always been intrigued by computers, software and computer games. At the tender age of 15, I had to decide, what job apprenticeship I wanted to take up: office clerk or information technology. Back then most information technology apprentices were boys, and I felt that I would feel out of place as the only girl in a class of 20+ students. As you can imagine, I decided to go for the office clerk education.
Fast forward fifteen years: I had just quit my job at a Zurich-based Start-up and had to decide, what I wanted to do next. Go back to managing IT projects and earning good money or invest time and money and learn how to build software? Play it safe or risk it?
I decided to listen to my heart and take a risk, and so I embarked on a journey to learn how to code.
I first started by teaching myself HTML and CSS and it turned out to be a straightforward thing to learn. The next step was JavaScript...not so straightforward. I learned just enough JavaScript and jQuery to get by, but I wasn’t happy with neither my learning pace nor my learning success. I was beginning to doubt my risky decision, and so I decided to give it one more shot: I enrolled in the Master21 Coding Bootcamp.
At this boot camp it just all fell into place, and that has a twofold reason: first of all, the fantastic instructor Rodrigo and second the programming language Ruby. It was the first time I had the feeling I could realistically reach my goal of learning to code.
Thanks to my boot camp instructor Rodrigo, I was approached by Simplificator employees and encouraged to apply for a job as a software developer. The multiple interviews I had at Simplificator were pretty tough, and it became apparent that I wasn’t yet at the level of a junior developer. Simplificator saw potential in me and offered me an internship as a software developer. Needless to say, I jumped at this opportunity to deepen my coding skills.
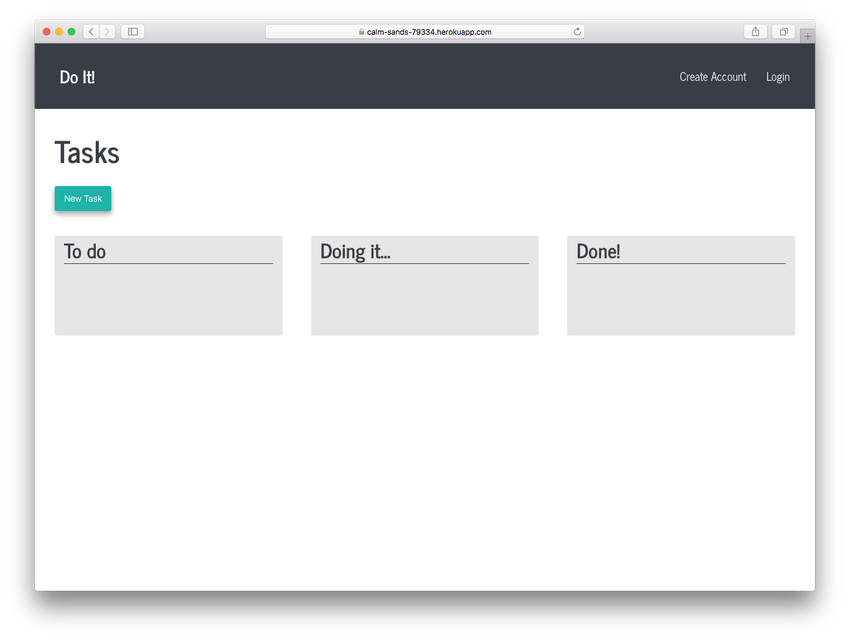
As a warm-up, I worked on my own little Ruby on Rails project and programmed a simple to do list. That work gave me the opportunity to both further my knowledge of Ruby and Ruby on Rails. I also learned how to use git and GitHub, Heroku, database management tools, IDE’s, etc.
I also got to do some frontend engineering on Simplificators own website.
My to do list built with Ruby on Rails
The next (big) step was building a productive tool for Simplificator. “Burn Rate” is crucial in planning our work on the different projects we work on. Thanks to the custom calculation formula, the software indicates how much time we have to work the next four weeks on the various projects to fulfill the requirements.
When the first development cycle of “Burn Rate” ended and we implemented it in production, I was so happy: Here was a useful tool programmed by myself (ok, I got some help here and there).
The third and last step was working on a project for an existing customer. It was challenging and exciting at the same time, as I worked on implementing new features in a previously existing web app. It was very helpful for my Ruby knowledge as I was reading and trying to understand code, which was written by other developers.
As the end of my internship approached the question arose “Should I stay or should I go?”. Well, I decided to stay and here’s why:
My internship made a developer out of me. But it will take time and lots of lines of code to make a good developer out of me.
My team here at Simplificator is simply awesome. They truly made a point of teaching me well how to go about when developing. Each team member is very different but we harmonize really well together.
My mentor Alessandro willingly shared his knowledge with me and always found the right words to motivate me. I’m sure I’ll learn a lot from him in the following years.
I believe in the philosophy of Simplificator:
Love what you do
Collaborate closely
Keep it simple
Dare to question
Get things done
I’m thankful for the chance Simplificator gave me.
I love playing foosball with my colleagues.
Was it worth going back to square one at 34 years of age? Yes, it was! Was it easy? Not at all. But aren’t the difficult things the most rewarding?
This post is about how to setup a WiFi with a Raspberry Pi 3. It describes what packages you have to install and one example is shown how to configure them. In the end you will have an Raspberry Pi 3, which is connected through ethernet to the internet. The Pi provides an SSID and takes care that the traffic between WiFi and Ethernet is forwarded.
Before you unmount the flashed card, create a file named ssh in the boot segment on the disk. Otherwise you won't be able to SSH into the Raspberry Pi.
Installations
Connect the Pi to your local network (through ethernet), search for the little rascal (i.e. using nmap) and connect to it via ssh.
When logged in, you will have to install at least 2 packages: dnsmasq and hostapd. I always love to have vim, so here's what I did:
Behold, that I used the address 10.0.0.1 as static IP. We will have to use the same IP for the DHCP configuration.
At this point you should quickly restart the networking service.
sudoservice networking restart
ifconfig wlan0 should then show the applied changes on in the wlan0 interface.
Configure DNSmasq
The Pi will have to manage the clients IP address (DHCP) on the wlan0 interface. I used DNSmasq for the DHCP server, but it should work fine with any other DHCP servers.
Note that the Pi's static IP address is used for listen-address and dhcp-option=option:router. For more information about that, consider reading http://www.thekelleys.org.uk/dnsmasq/doc.html. ;-)
Portforwarding (route wlan0 to eth0)
The next step affects iptables. I am no expert in this, so I basically just copy pasted that stuff and ensured that the in -i and out -o parameters made sense.
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
sudo iptables -A FORWARD -i eth0 -o wlan0 -m state --state RELATED,ESTABLISHED -j ACCEPT
sudo iptables -A FORWARD -i wlan0 -o eth0 -j ACCEPT
In a nutshell, it allows that general traffic/communication is allowed between the interfaces wlan0 (wireless) and eth0 (ethernet). In order that the iptables rules apply immediately, you'll have to do this:
sudo sh -c "echo 1 > /proc/sys/net/ipv4/ip_forward"
In order that the iptables rules are considered after reboot, edit /etc/sysctl.conf, and uncomment this line:
net.ipv4.ip_forward=1
Finally persist the iptables rules, otherwise they get truncated after reboot. I used a package iptables-persistent which persists the rules right during installation which is pretty convenient.
sudo apt-get install iptables-persistent
Configure the access point
Now it get's interesting. We can create our own SSID and define a password. Therefore create /etc/hostapd/hostapd.conf and paste and save this:
interface=wlan0 driver=nl80211
ssid=SIMPLIFICATOR-WIFI
hw_mode=g
channel=6
macaddr_acl=0
auth_algs=1
ignore_broadcast_ssid=0
wpa=2
wpa_passphrase=YOUR-INCREDIBLY-SECURE-PASSWORD
wpa_key_mgmt=WPA-PSK
#wpa_pairwise=TKIP # You better do not use this weak encryption (only used by old client devices)
rsn_pairwise=CCMP
ieee80211n=1 # 802.11n support
wmm_enabled=1 # QoS support
ht_capab=[HT40][SHORT-GI-20][DSSS_CCK-40]
Let's connect the above config to the default hostapd config, edit /etc/default/hostapd and make sure DAEMON_CONF is uncommented and points to the config file.
DAEMON_CONF="/etc/hostapd/hostapd.conf"
Services (hostapd & dnsmasq)
Lastly, let's restart the services and enable them, so that the start automatically on boot.
sudo service hostapd restart
sudo service dnsmasq restart
sudo update-rc.d hostapd enable
sudo update-rc.d dnsmasq enable
That's it
You should now see a WiFi named SIMPLIFICATOR-WIFI and connect to it using the passphrase YOUR-INCREDIBLY-SECURE-PASSWORD, or whatever values you have given it.
Insights
While writing the blog post I had several insights:
Raspberry Pi 3 comes with an 2.4 GHz 802.11n (150 Mbit/s) WiFi. It's always good to know the limits of the bandwidth.
Even if you used a WiFi USB adapater with 1000 Mbit/s, the maximum speed would be 480 Mbit/s because of the USB 2 interface (!)
I wasn't able to configure the Pi, so that two WiFi dongles run simultaneously, so that you could extend the range of an existing WiFi without having the Pi connected to an ethernet cable.
When it comes to software versioning, you normally do not want to upload passwords or secrets into shared repositories. Too many people might have access to the code, and it's irresponsible to have secrets there without protection.
On the other hand, you actually do want to share such secrets among certain co-workers (the "circle of trust", implying that all other co-workers are not trustworthy 😉).
So, what we want are "protected" secrets in our versioning control system, that only the circle of trust has access to.
We are going to identify our files to be protect and encrypt them with Ansible. The encryption bases on a password, that we share with the people who may know our secrets. So, this password is chosen once and used for the same file "forever".
Encrypt 🔐
Let's say we store our secrets in a file named secrets.yml, and the content looks like this
favorite_artists:
- Lady Gaga
- Justin Bieber
- Kanye West
Obviusly no one should ever know that we like those artists, but the circle of trust may know, if necessary.
Now we can use ansible-vault encrypt to encrypt our secrets.
pi@raspberrypi:~ $ cat ./secrets.yml favorite_artists: - Lady Gaga - Justin Bieber - Kanye West
pi@raspberrypi:~ $ ansible-vault encrypt ./secrets.yml Vault password: # enter a vault password here Encryption successful
Behold where it asks to enter a vault password (# enter a vault password here). We've chosen a wise, complicated password (= foo), and can now share this with the people in the circle of trust.
Further, we can check in secrets.yml and upload it to our versioning control system.
Decrypt
Of course, at some point we will have to decrypt secrets.yml, we do this:
pi@raspberrypi:~ $ ansible-vault decrypt ./secrets.yml Vault password: # enter the vault password here Decryption successful
pi@raspberrypi:~ $ cat ./secrets.yml favorite_artists: - Lady Gaga - Justin Bieber - Kanye West
That's the whole magic.
One more thing
Don't be confused that you'll get different contents of encrypted files, without changing the original content (and same vault password).
Eencrypt the file with foo twice, save the corresponding outputs to ./secrets1.yml and ./secrets\2.yml
pi@raspberrypi:~ $ cat ./secrets.yml favorite_artists: - Lady Gaga - Justin Bieber - Kanye West
We have two meeting rooms at our Simplificator headquarter office in central Zurich. As they have opaque doors and no windows towards the aisle, it was often unclear whether a meeting room was occupied or not. Frequently, people opened the door and immediately apologized when realizing that there was an ongoing meeting. As an agile company we strive to reduce such nuisances and to improve our efficiency.
We, the “Smooth Operators” team, came up with an idea to improve the situation by mounting a display next to the door of each meeting room showing its occupancy. A 3-day retreat was planned to focus our efforts on this project.
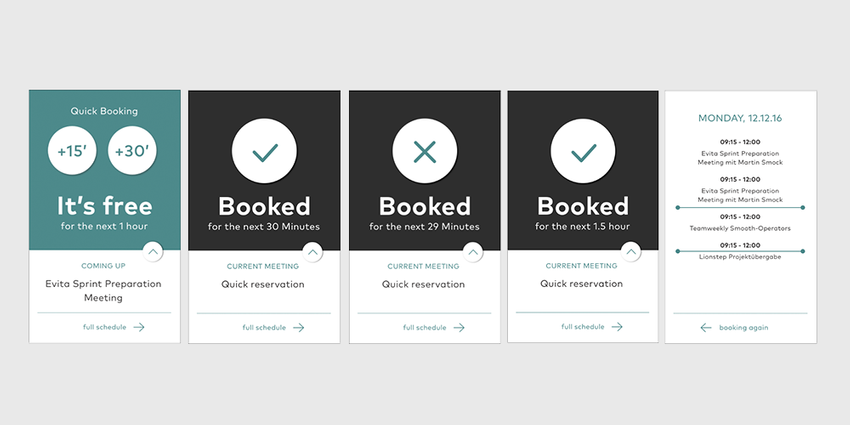
We decided to use a Raspberry Pi 3 with its official touch screen display. This allowed us to not only display information, but to make the system interactive. We started out by brainstorming the functionality we wanted to provide to the user. Most importantly, it should be obvious whether the meeting room was occupied or not. Scheduled meetings of the current day should be visible and we wanted to provide the ability to make a “quick reservation”, i.e. anonymously book the room for 15 or 30min. This feature is quite useful if you want to have a short ad-hoc talk or a quick phone call. As we already schedule meetings in Simplificator’s Google Calendar, we fetch booking data from the Google Calendar API.
After defining the functionality, we created wireframes to clarify how many screens we would have to implement and what information and interactivity they should provide. We ended up having two screens: the main screen showing whether the room is free or busy and a screen showing all scheduled meetings of the current day. As the functionality and the screens were defined, our designer started to layout the screens and define its components graphically. We tested the design on the display of the Raspberry Pi regarding size and colors and performed quick user tests to finetune the behavior.
Each screen has several possible states (e.g. free and busy), so we decided to use an interactive web frontend technology. As retreats at Simplificator offer an educational component as well, we decided to create two versions of the app, one in React and one in Elm. To run the app in a kiosk mode on the Raspberry Pi, we chose to package our app with Electron.
After the three days of retreat we had two basic apps in React and Elm. For future maintainability we decided to go on with the React app. We mounted the Raspberry Pis and their display next to the meeting room doors, installed our app on them and tested for a while. We found some bugs to fix and improvements to implement. The app is now running quite smoothly and our meetings are free of disturbances!
If you want to rebuild this setup at your office as well, you find the required hardware components and a link to the app’s code below. Drop us a line and tell us how it is working out for you!
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, it gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
What is Hanami?
Hanami is a Ruby MVC web framework comprised of many micro-libraries. It has a simple, stable API, a minimal DSL, and prioritises the use of plain objects over magical, over-complicated classes with too much responsibility.
The natural repercussion of using simple objects with clear responsibilities is more boilerplate code. Hanami provides ways to mitigate this extra legwork while maintaining the underlying implementation.
Project setup
If you haven't already done so, install hanami.
gem install hanami
After hanami is installed on your machine, you can create a new project. Feel free to chose another database or test framework if you like.
hanami new blogs --database=postgres --application-name=api --test=rspec cd blogs
Define entities
Before we do anything at all, we need entities we can query over our API. Hanami offers a generator for entities which can be invoked by the following command:
hanami generate model author
This will generate an entity and the corresponding test. In this tutorial tests are omitted for brevity but you are encouraged to implement them on your own.
We start out with our author as it's a very simple model. It has a single attribute 'name'.
# lib/blogs/entities/author.rb
classAuthor includeHanami::Entity
attributes :name end
Next we're going to generate another model. A blog.
hanami generate model blog
For our blog, we want a title, content and an author_id to reference the author.
# lib/blogs/entities/blog.rb
classBlog includeHanami::Entity
attributes :title,:content,:author_id end
Update database
To be able to store entities, we need to define database tables to hold data. Create a migration for the author model first:
hanami generate migration create_authors
Hanami will generate a migration file with a current timestamp for you under db/migrations. Open the file and add the following:
Hanami::Model.migration do change do create_table :authorsdo primary_key :id column :name,String, null:false end end end
For blogs, we create another migration named create_blog.
hanami generate migration create_blogs
Inside the migration create another table with columns for our blog:
Hanami::Model.migration do change do create_table :blogsdo primary_key :id column :title,String, null:false column :content,String, null:false foreign_key :author_id,:authors end end end
To get the changes to our database, execute
hanami db create hanami db migrate
In order to be able to run database-backed tests, we need to ensure that the test database uses the same schema as our development database. Update the schema by setting HANAMI_ENV to test explicitly:
HANAMI_ENV=test hanami db create HANAMI_ENV=test hanami db migrate
Now that our database is ready, we can go ahead and define mappings for author and blog. Go to lib/blogs.rb, find the mapping section and add mappings for the new entities.
## # Database mapping # # Intended for specifying application wide mappings. # mapping do collection :blogsdo entity Blog repository BlogRepository
attribute :id,Integer attribute :title,String attribute :content,String attribute :author_id,Integer end
attribute :id,Integer attribute :name,String end end
Introducing Types
After having defined our entities, we can now move on to create GraphQL types. First update your Gemfile and add the following line:
gem 'graphql'
and then run
bundle install
We're going to place type definitions in a dedicated directory to keep them separate from our entities. Furthermore those types are relevant for our web API only and not for the whole application. Create a directory in apps/api/ named types
mkdir -p apps/api/types
and update your web app's application.rb file to include type definitions in the load path.
Notice the require_relative statements at the beginning of some files. This is a workaround because, even though defined in the load path, types don't seem to be auto loaded inside a type definition file.
... and Action
Now that the schema definitions and load path are set up correctly, it is time to create the action that will serve query requests. To generate a new action invoke the following command:
hanami generate action api graphql#show --skip-view
Since we're providing the --skip-view flag Hanami will not generate a view class and template for this action. The above command will generate a new action where we place query logic.
defcall(params) query_variables = params[:vairables]||{} self.body =JSON.generate( BlogSchema.execute( params[:query], variables: query_variables ) ) end end end
To let Hanami know that it shouldn't render a view, we set self.body directly inside the action.
Query the API
In order to see the API working, we need data! Fire up your hanami console and create some author and blogs.
hanami c
Now create one or more authors and save it to database via AuthorRepository:
Go ahead and play around with the query. If you look at the type definition for QueryType you'll notice, that it should be possible to query for authors, too. Can you get the API to list all blog titles for a given author?
That's it. This introduction should give you a glimpse into Hanami and GraphQL. You can find more information in the section below.
When I finished my Master in Economics in September 2014, I didn't want to take on some random office job where I do the same every day. I wanted a job where I have to learn something every day and where I have to keep up to date with what I do. I then decided to take on a 50% accounting job, in order to make a living, and meanwhile, I decided to learn programming. I started with online tutorials and practised on my own. However, I soon realised that, at some point, I didn't get any further. I had a basic knowledge about data structures and control structures, but I had no idea where I would have to use them in a real project.
In early 2015, I then looked at different companies and it soon became clear to me that I wanted to work at Simplificator. When I called to ask for an internship, I was told that Simplificator doesn't have any internship positions. I then thought about applying at a different company, but I really just wanted to work at Simplificator. So I sent an email to Lukas (the CEO), asking again. They then invited me for a short interview and they agreed that I could start a 50% internship the next week.
During my internship, Tobias was my team lead and instructor. He taught me about classes, methods, design patterns and much more. Especially at the beginning, I had to learn a lot of different technologies: Ruby, Rails, SQL, HTML, CSS etc. Soon, I started my own little project, which was a calorie tracker. The calorie tracker was a very good way to learn new things as the project developed. I started with the backend, so that the business logic was implemented as discussed with the "client", who was Tobias. The frontend didn't look nice at all. I only used it to test if my backend works as intended. I then received a design from our designer Marcel, which I had to implement. This was very important, because I knew that it also works like this in real projects.
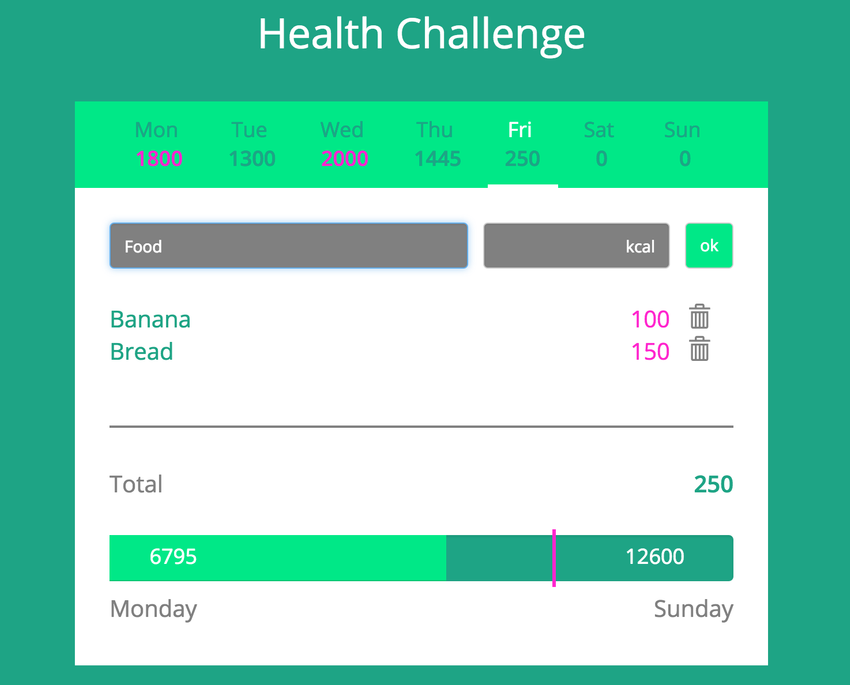
This is what the calorie tracker looked like after I implemented the design:
Later, I wrote unit tests and integration tests, as well as controller tests for the calorie tracker. As a next step, users were introduced, so several people would be able to use the calorie tracker. This was quite tricky for me, because I had never worked with sessions before. But again, I knew this would be important in real projects, too. Next, there should be a date picker, where the user could jump to the requested day.
Another requirement was that the user should be able to add a new entry without the page needing to reload every time. This was probably the hardest part, as I had to learn jQuery and the concept of AJAX at the same time. However, it worked out and the user experience was much better than before.
I really liked the calorie tracker project, because I learned so many things that would be useful in later real-life projects. Also, it was nice to see that the calorie tracker developed along with my programming skills. I implemented the easiest features in the beginning and they became much more fancy, as I learned new concepts and technologies. I also had a small insight of how a real project would work. I had to deal with the customer not yet being sure about what he really wants and thus, with changing requirements. It was a great way to develop my programming skills.
I want to thank Tobias for his great guidance to smooth operating, clean code and coding methodology. I learned so much in this year that I will be able to use for my whole programming career now. But it was not only Tobias who was helpful to me during my internship. Actually, everybody at Simplificator was always happy to help me with questions and giving me guidance in everything they could. I am still so happy to have had the opportunity for this internship, even though such a position didn't actually exist. This is exactly how I perceived Simplificator from the beginning: People are always open for new ideas, even from outside people like me, at that time.
Since September, I have been working at Simplificator as a full-time Junior Software Developer, and I am working on much more challenging projects now. It is always interesting and I am still learning every day. Just like I always wanted :-)